
You need to understand how:
- Search engines crawl and index websites.
- Search algorithms function.
- Search engines treat user intent as a ranking signal (and where they’re likely going with it).
Now, the term “machine learning” gets thrown around a lot these days.
But how does machine learning actually impact search and SEO?
This article will explore everything you need to know about how search engines use machine learning.
What Is Machine Learning?

It would be difficult to understand how search engines use machine learning without knowing what machine learning actually is.
Let’s start with the definition (provided by Stanford University in their course description for Coursera) before we move on to a practical explanation:
“Machine learning is the science of getting computers to act without being explicitly programmed.”
A Quick Aside Before We Continue …
Machine learning isn’t the same as Artificial Intelligence (AI), but the line is starting to get a bit blurry with the applications.As noted above, machine learning is the science of getting computers to come to conclusions based on information but without being specifically programmed in how to accomplish said task.
AI, on the other hand, is the science behind creating systems that either have, or appear to possess, human-like intelligence and process information in a similar manner.
Think of the difference this way:
Machine learning is a system designed to solve a problem. It works mathematically to produce the solution. The solution could be programmed specifically, or worked out by humans manually, but without this need, the solutions come much faster.
A good example would be setting a machine off to pour through oodles of data outlining tumor size and location without programming in what it’s looking for. The machine would be given a list of known benign and malignant conclusions. With this, we would then ask the system to produce a predictive model for future encounters with tumors to generate odds in advance as to which it is based on the data analyzed.
This is purely mathematical.
A few hundred mathematicians could do this – but it would take them many years (assuming a very large database) and hopefully none of them would make any errors. Or, this same task could be accomplished with machine learning – in far less time.
When I’m thinking of Artificial Intelligence, on the other hand, that’s when I start to think of a system that touches on the creative and thus becomes less predictable.
An artificial intelligence set on the same task may simply reference documents on the subject and pull conclusions from previous studies. Or it may add new data into mix. Or may start working on a new system of electrical engine, foregoing the initial task. It probably won’t get distracted on Facebook, but you get where I’m going.
The key word is intelligence. While artificial, to meet the criteria it would have to be real thus producing variables and unknowns akin to what we encounter when we interact with others around us.
Back to Machine Learning & Search Engines
Right now what the search engines (and most scientists) are pushing to evolve is machine learning.Google has a free course on it, has made its machine learning framework TensorFlow open source, and is making big investments in hardware to run it.
Basically, this is the future so it’s best to understand it.
While we can’t possibly list (or even know) every application of machine learning going on over at the Googleplex, let’s look at a couple of known examples:
RankBrain
What article on machine learning at Google would be complete without mentioning their first and still highly-relevant implementation of a machine learning algorithm into search?That’s right … we’re talking RankBrain.
Essentially the system was armed only with an understanding of entities (a thing or concept that is singular, unique, well-defined and distinguishable) and tasked with producing an understanding of how those entities connect in a query to assist in better understanding the query and a set of known good answers.
These are brutally simplified explanations of both entities and RankBrain but it serves our purposes here.
So, Google gave the system some data (queries) and likely a set of known entities. I’m going to guess on the next process but logically the system would then be tasked with training itself based on the seed set of entities on how to recognize unknown entities it encounters. The system would be pretty useless if it wasn’t able to understand a new movie name, date, etc.
Once the system had that process down and was producing satisfactory results they would have then tasked it with teaching itself how to understand the relationships between entities and what data is being implied or directly requested and seek out appropriate results in the index.
This system solves many problems that plagued Google.
The requirement to include keywords like “How do I replace my S7 screen” on a page about replacing one should not be necessary. You also shouldn’t have to include “fix” if you’ve included “replace” as, in this context, they generally imply the same thing.
RankBrain uses machine learning to:
- Continuously learn about the connectedness of entities and their relationships.
- Understand when words are synonyms and when they are not (replace and fix may be synonyms in this case but they wouldn’t be if I was querying “how to fix my car”).
- Instruct other portions of the algorithm to produce the correct SERP.
If RankBrain can improve results for queries that likely weren’t optimized for and will involve a mix of old and new entities and services a grouping of users who were likely getting lackluster results to begin with then it should be deployed globally.
And it was in 2016.
Let’s take a look at the two results I referenced above (and worth noting, I was writing the piece and the example and then thought to get the screen capture – this is simply how it works and try it yourself … it works in almost all cases where different wording implies the same thing):
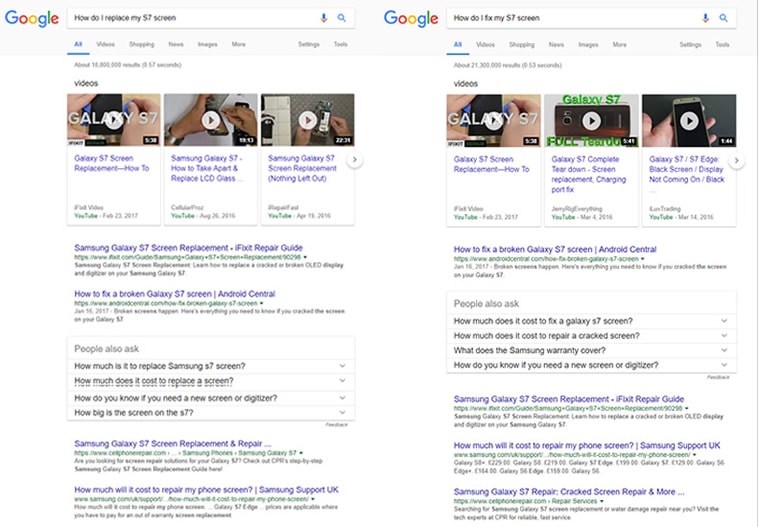
Some very subtle differences in rankings with the #1 and 2 sites switching places but at its core it’s the same result.
Now let’s look at my automotive example:
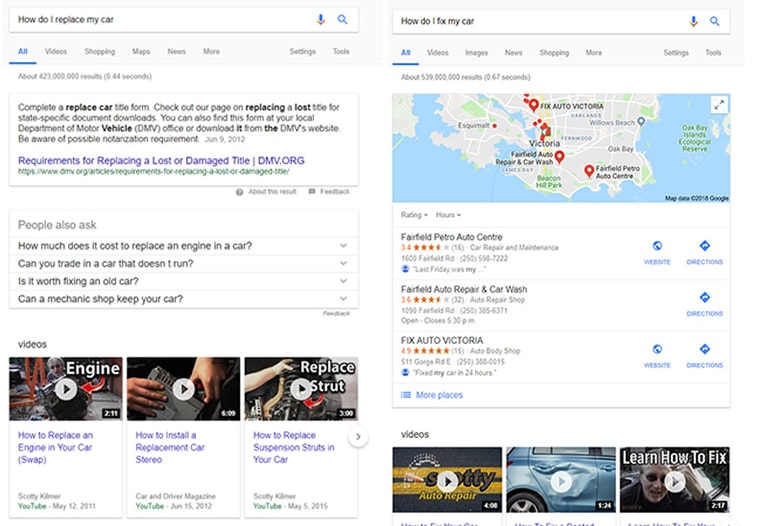
Machine learning helps Google to not just understand where there are similarities in queries, but we can also see it determining that if I need my car fixed I may need a mechanic (good call Google), whereas for replacing it I may be referring to parts or in need of governmental documentation to replace the entire thing.
We can also see here where machine learning hasn’t quite figured it all out.
When I ask it how to replace my car, I likely mean the whole thing or I’d have listed the part I wanted. But it’ll learn … it’s still in its infancy. Also, I’m Canadian, so the DMV doesn’t really apply.
So here we’ve seen an example of machine learning at play in determining query meaning, SERP layout, and possible necessary courses of action to fulfill my intent.
Not all of that is RankBrain, but it’s all machine learning.
Spam
If you use Gmail, or pretty much any other email system, you also are seeing machine learning at work.According to Google, they are now blocking 99.9 percent of all spam and phishing emails with a false-positive rate of only 0.05 percent.
They’re doing this using the same core technique – give the machine learning system some data and let it go.
If one was to manually program in all the permutations that would yield a 99.9 percent success rate in spam filtering and adjust on the fly for new techniques it would be an onerous task if at all possible. When they did things this way they sat at a 97 percent success rate with 1 percent of false positive (meaning 1 percent of your real messages were sent to the spam folder – unacceptable if it was important).
Enter machine learning – set it up with all the spam messages you can positively confirm, let it build a model around what similarities they have, enter in some new messages and give it a reward for successfully selecting spam messages on its own and over time (and not a lot of it) it will learn far more signals and react far faster than a human ever could.
Set it to watch for user interactions with new email structures and when it learns that there is a new spam technique being used, add it to the mix and filter not just those emails but emails using similar techniques to the spam folder.
So How Does Machine Learning Work?
This article promised to be an explanation of machine learning, not just a list of examples.The examples, however, were necessary to illustrate a fairly easy-to-explain model.
Let’s not confuse this with easy to build, just simple in what we need to know.
A common machine learning model follows the following sequence:
- Give the system a set of known data. That is, a set of data with a large array of possible variables connected to a known positive or negative result. This is used to train the system and give it a starting point. Basically, it now understands how to recognize and weigh factors based on the past data to produce a positive result.
- Set up a reward for success. Once the system is conditioned with the starting data it is then fed new data but without the known positive or negative result. The system does not know the relationships of a new entity or whether an email is spam or not. When it selects correctly it is given a reward though clearly not a chocolate bar. An example would be to give the system a reward value with a goal of hitting the highest number possible. Each time it selects the right answer this score is added to.
- Set it loose. Once the success metrics are high enough to surpass existing systems or meet another threshold the machine learning system can be integrated with the algorithm as a whole.
Another model of machine learning is the Unsupervised Model. To draw from the example used in a great course over on Coursera on machine learning, this is the model used to group similar stories in Google News and one can infer that it’s used in other places like the identification and grouping of images containing the same or similar people in Google Images.
In this model, the system is not told what it’s looking for but rather simply instructed to group entities (an image, article, etc.) into groups by similar traits (the entities they contain, keywords, relationships, authors, etc.)
Why Does This Matter?
Understanding what machine learning is will be crucial if you seek to understand why and how SERPs are laid out and why pages rank where they do.It’s one thing to understand an algorithmic factor – which is an important thing to be sure – but understanding the system in which those factors are weighted is of equal, if not greater, importance.
For example, if I was working for a company that sold cars I would pay specific attention to the lack of usable, relevant information in the SERP results to the query illustrated above. The result is clearly not a success. Discover what content would be a success and generate it.
Pay attention to the types of content that Google feels may fulfill a user’s intent (post, image, news, video, shopping, featured snippet, etc.) and work to provide it.
I like to think of machine learning and its evolution equivalent to having a Google engineer sitting behind every searcher, adjusting what they see and how they see it before it is sent to their device. But better – that engineer is connected like the Borg to every other engineer learning from global rules.
Reference:https://www.searchenginejournal.com/how-machine-learning-in-search-works/257837/?ver=257837X3
Thanks for sharing this great article..Its really nice and useful for us.Web Designing Company Bangalore | Website Design Company Bangalore
ReplyDelete