
Optimizing websites without first understanding how search engines function is akin to publishing your great novel without first learning how to write.
Certainly a thousand monkeys at typewriters will eventually create something useful (at least this monkey likes to think he does from time to time), but it’s a lot easier if you know the core elements of a task beforehand.
So we must understand how search engines work to fully understand how to optimize for them.
While we will be focusing on organic search, we must first briefly talk about one critical truth about search engines.
Paid Search Results
Not Google, not Bing, nor any other major search engine is in the business of providing organic listings.That is to say, organic results are the means to the end, but do not directly generate revenue for Google.
Without organic search results Google’s paid search results would appear less relevant, thus reducing eyeballs and paid clicks.
Basically, Google and Bing (and the others) are advertising engines that happen to draw users to their properties with organic listings. Organic, then, is the means to the end.
Why does this matter?
It’s the key point driving:
- Their layout changes.
- The existence of search features like knowledge panels and featured snippets.
- The click-through rates (CTR) of organic results.
When Google displays a featured snippet so you don’t have to leave Google.com to get an answer to your query… it is because of this.
Regardless of what change you may see taking place it’s important to keep this in mind and always question not just what it will impact today but what further changes do they imply may be on the horizon.
How Search Engines Work Today: The Series
Alright, now that we have that baseline understanding of why Google even provides organic results let’s look at the nuts-and-bolts of how they operate.To accomplish this we’re going to look at:
- Crawling and indexing
- Algorithms
- Machine learning
- User intent
Indexing
Indexing is where it all begins.For the uninitiated, indexing essentially refers to the adding of a webpage’s content into Google.
When you create a new page on your site there are a number of ways it can be indexed.
The simplest method of getting a page indexed is to do absolutely nothing.
Google has crawlers following links and thus, provided your site is in the index already and that the new content is linked to from within your site, Google will eventually discover it and add it to its index. More on this later.
But what if you want Googlebot to your page faster?
This can be important if you have timely content or if you’ve made an important change to a page you need Google to know about.
One of the top reasons I use faster methods is when I’ve either optimized a critical page or I’ve adjusted the title and/or description to improve click-throughs and want to know specifically when they were picked up and displayed in the SERPs to know where the measurement of improvement starts.
In these instances there a few additional methods you can use:
1. XML Sitemaps
There are always XML sitemaps.Basically, this is a sitemap that is submitted to Google via Search Console.
An XML sitemap gives search engines a list of all the pages on your site, as well as additional details about it such as when it was last modified.
Definitely recommended!
But when you need a page indexed immediately?
It’s not particularly reliable.
2. Fetch and Render
In Search Console (the old version, and presumably in the new version), you can “Fetch as Google”.In the left navigation, simply click Crawl > Fetch as Google.
Enter the URL you want indexed, then click Fetch.
After it’s fetched your URL you’ll be presented with the option to “Request Indexing.”
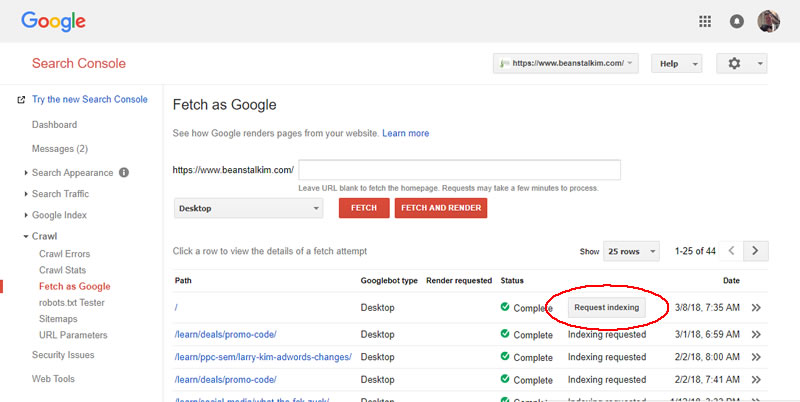
Click the button.
Generally within a few seconds to a few minutes you can search the new content or URL in Google and find the change or new content picked up.
3. Submit URL to Google
Too lazy to log into Search Console or want your shiny new content on a third party site to get picked up quickly?Just Google it.
Simply Google [submit URL to Google] and you’ll be presented with a URL submission field:
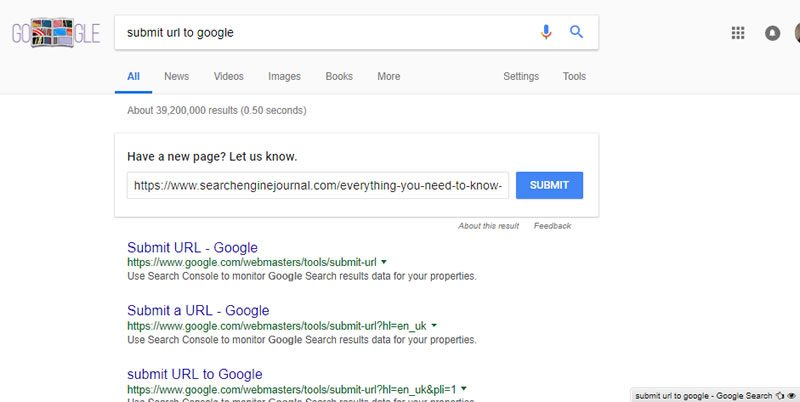
It seems to work about as quickly as going through the Search Console.
To be fair, you can do the same with Bing here.
4. Google Plus
You know there had to be some reason to use it right?Posting a new URL into Google Plus will see it indexed in seconds.
Google has to fetch the URL to pull the images, description, etc. and in doing so discovers it if it wasn’t already known.
This is probably the second faster way to get content indexed by Google.
The fastest (and often least doable) way is…
5. Host Your Content On Google
Crawling sites to index them is a time and resource consuming process.One alternative is to host your content directly with them.
This can be done a few different ways but most of us (myself included) have not adopted the technologies or approaches required and Google hasn’t pushed us to them.
We’re seeing the ability to give Google direct access to our content via XML feeds, APIs, etc. and unplug our content from our design.
Firebase, Google’s mobile app platform, gives Google direct access to the app content, bypassing any need to figure out how to crawl it.
This is the future – enabling Google to index content immediately, without effort, so it can then serve it in the format most usable based on the accessing technology.
While we aren’t quite where we need to be in our technologies to stress too much about this side of things, just know it is coming.
I cannot recommend enough following Cindy Krum’s Mobile Moxie blog, where she discusses these and mobile-related subjects in great detail and with great insight.
So – that’s almost everything what you need to know about indexing and how search engines do it (with an eye towards where things are going).
Crawl Budget
We can’t really talk about indexing without talking about crawl budget.Basically, crawl budget is a term used to describe the amount of resources that Google will expend crawling a website.
The budget assigned is based on a combination of factors, the two central ones being:
- How fast your server is (i.e., how much can Google crawl without degrading your user experience).
- How important your site is.
If you run a small barber shop, have a couple dozen links, and rightfully are not deemed important in this context (you may be an important barber in the area but you’re not important when it comes to crawl budget) then the budget will be low.
You can read more about crawl budgets and how they’re determined in Google’s explanation here.
Reference:https://www.searchenginejournal.com/how-search-engines-crawl-index-everything-you-need-to-know/241855/
No comments:
Post a Comment